2.7 Graph Building - Data Importer
The DataImporter is the interface where the user can define the mapping between the extracted source objects the the Target Entities.
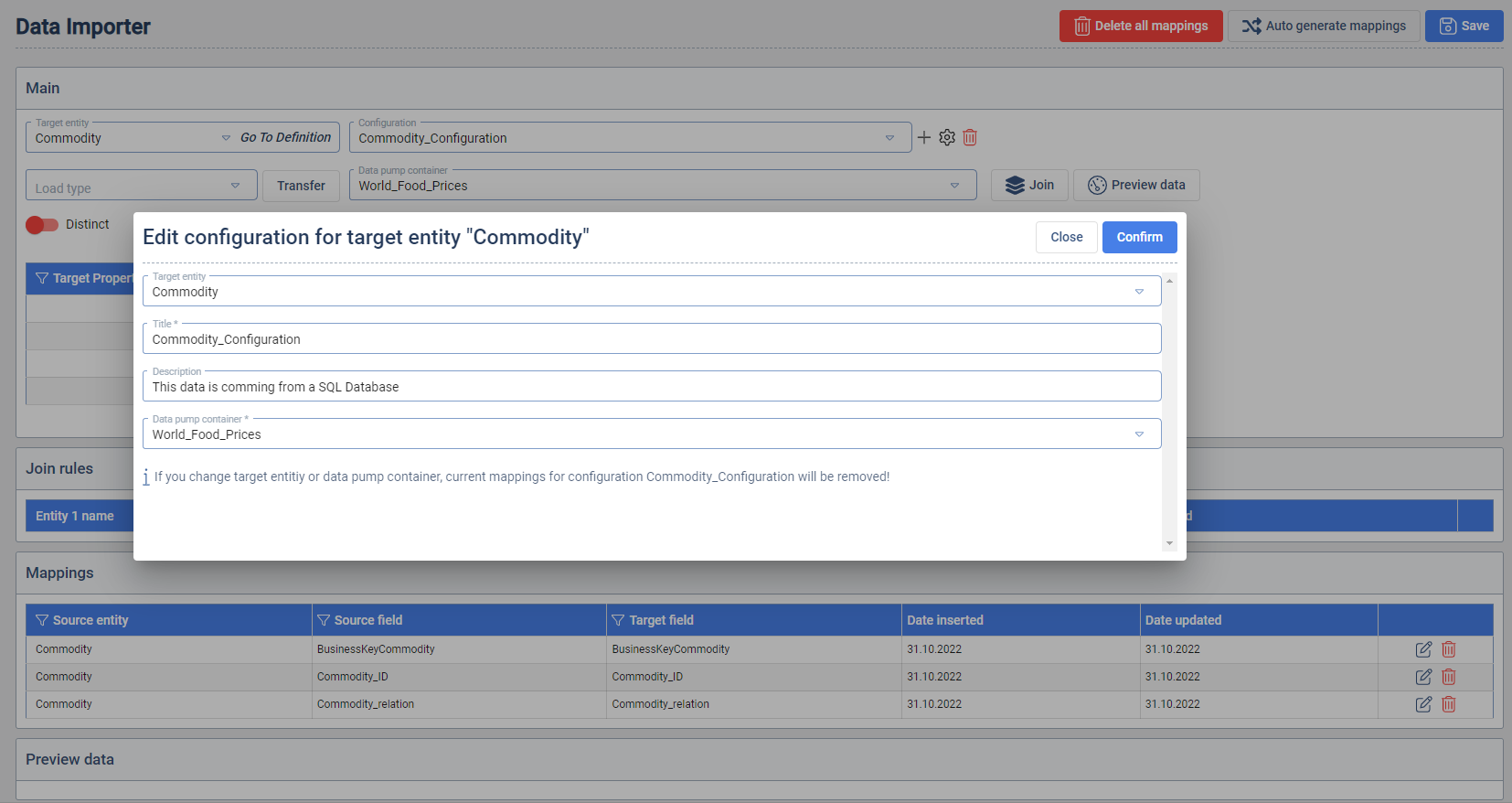
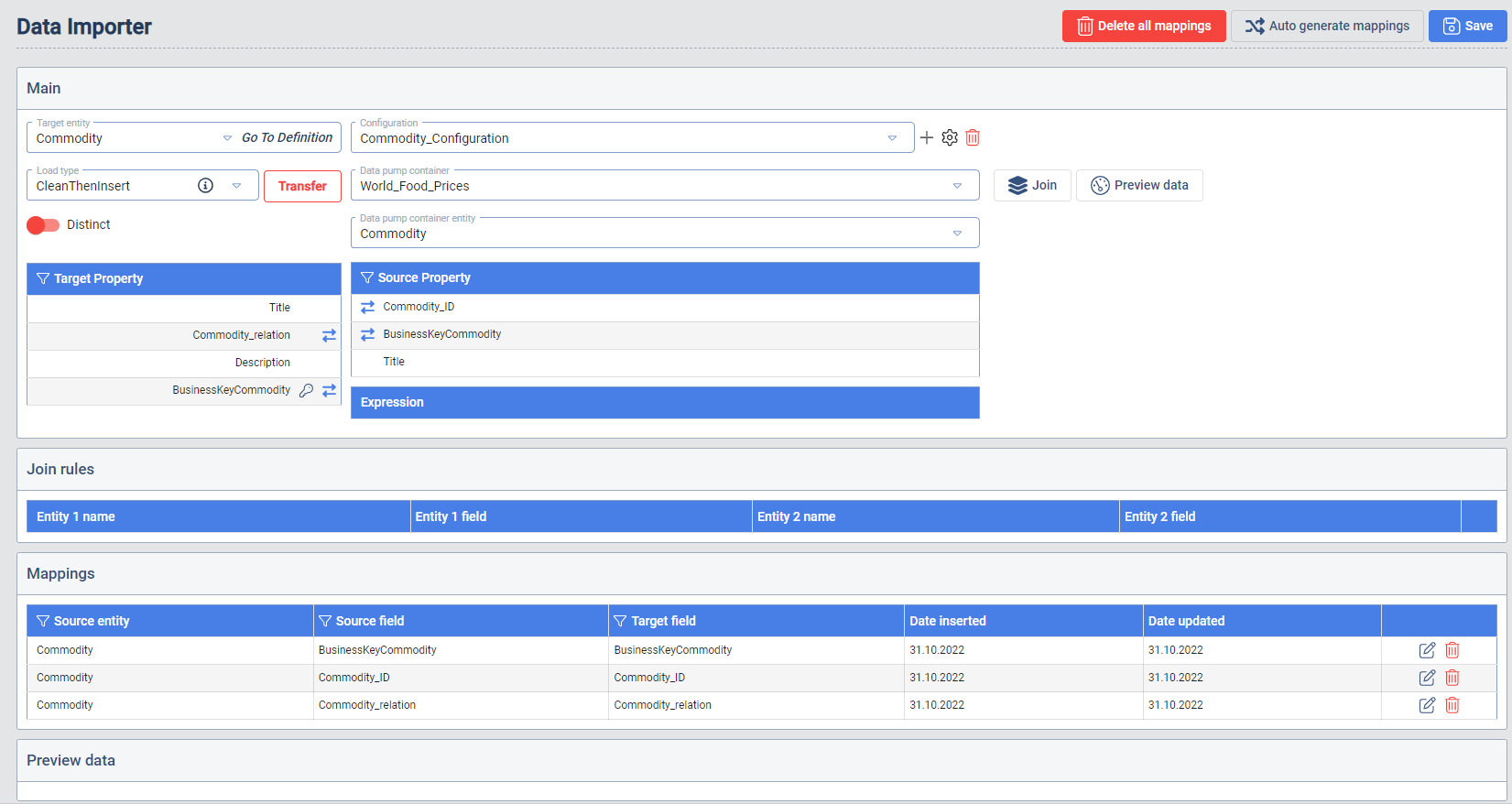
Data Importer
In the first step the user needs to select the Target Entity. After the selection the properties appear and can be mapped to the available sources.
The available source depends on the selected Data Pump Container and Data Pump container entity. When the source entity is selected the properties are available. The mapping is set with the selection of one target property and one source property. When the properties are selected a Map properties button appears. When a mapping is created it appears in the Mappings table.
The mapping can be individually edited or deleted. In case the user wants to delete all the mappings the Delete all mappings button needs to be clicked.
Distinct: When a mapping configuration is marked as distinct, the transferred rows of data will be checked and filtered for duplicates. All columns are taken into account when the uniqueness is determined.
Load Type: This selection determines the type of transferring the data between the source and the staging layer.
-
CleanThenInsert: In this case all the data in the Target Entity is deleted when the Transfer (Load) is triggered.
-
Insert Only: In this case the data from the source will only be inserted into the Target Entity. In case the Target Entity already contains a row with an existing Business key, no update is performed. In case a duplicated business key case appears, the data transfer will result in an error.
-
Merge: In this case the data from the source is compared with the data already present in the Target Entity. In case there is a match an update is performed. In case a Business key is not yet present, a new row is added. In case the source data does not contain an business key which is contained in the Target Entity, Data Context Hub will delete the row for the Target Entity.
-
Preserving Merge: In this case the data from the source is compared with the data already present in the Target Entity. In case there is a match an update is performed. In case a Business key is not yet present, a new row is added. In case the source data does not contain an Business key which is contained in the Target Entity, Data Context Hub will not delete the row for the Target Entity.
-
Update Only: In this case the data from the source is compared with the data already present in the Target Entity. In this case only the data of already existing Business keys will be inserted. Not matching Business keys will not be touched, new Business keys will not be added. This Load type will not import data, when entity is empty or no Business key matches.
Preview data: Show a preview of the data selected Data Pump Source entity.
Auto generate mappings: This will generate mapping automatically based on the matching name of the properties from the source and Target Entities.
Expressions
The Data Importer enables the definition of Expression which are constructed based properties in the source entities. Expressions enables that dynamic property values are combined with each other and also combined with static strings. When saved, a new source property is available to be mapped on of the properties of the Target Entity. To use the Expressions a Worker that supports Expressions has to be installed in the GBS.
String Expressions: To concatenate properties that are a string, use the + operator.
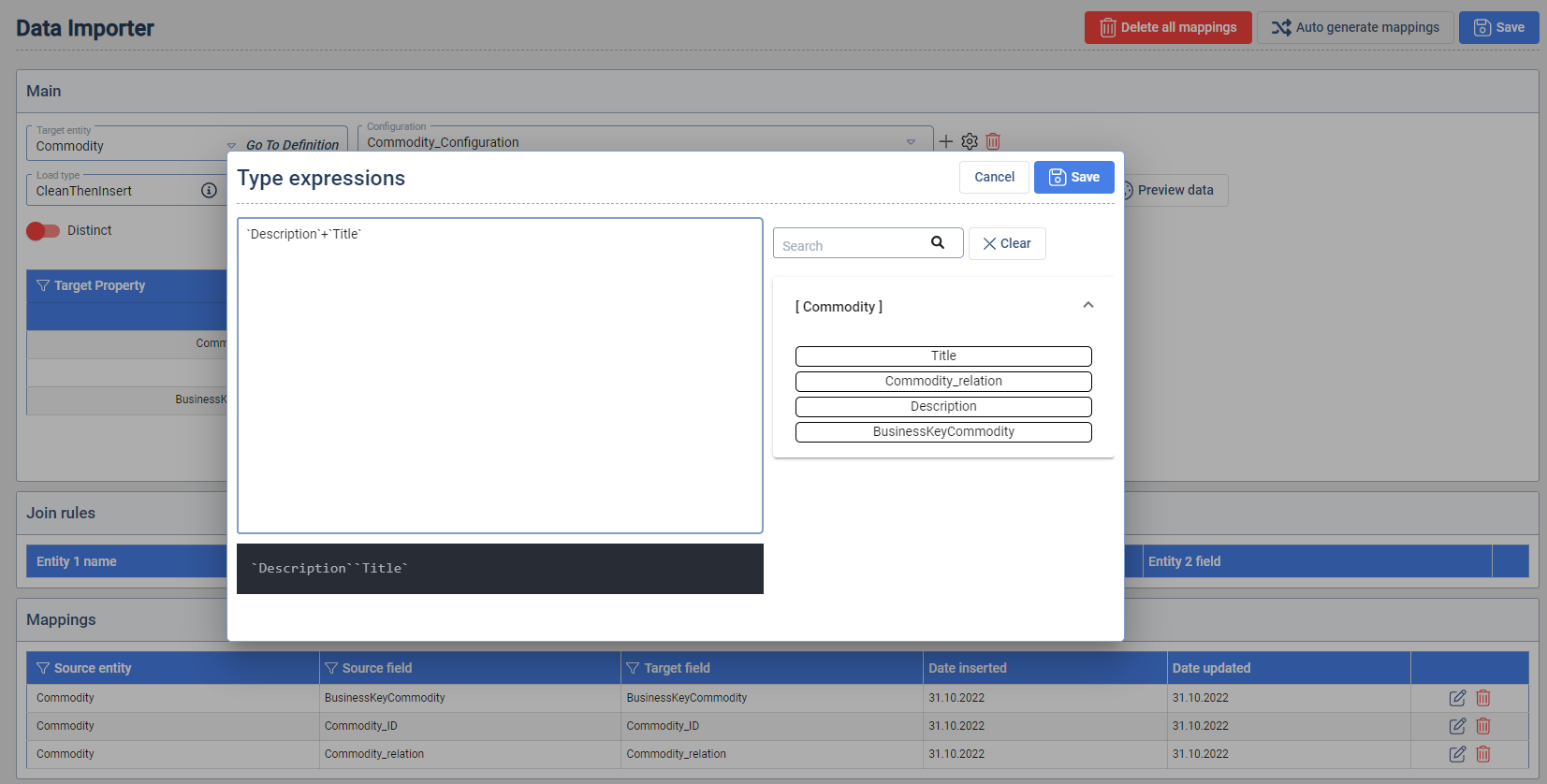
Examples:
- String and property:
"hello" + propertyA - Property and property:
propertyA + propertyB
Limitations: The Expressions Worker has limitations regarding certain characters and combinations.
- All Special characters outside the Unicode (U+0001..U+007F → basic latin letters)
- Unable to take a N amount of characters, e.g.
"property1"[:2]to take the first 2 characters - Paragraph character
§cannot be used in a string e.g."Hello§world"
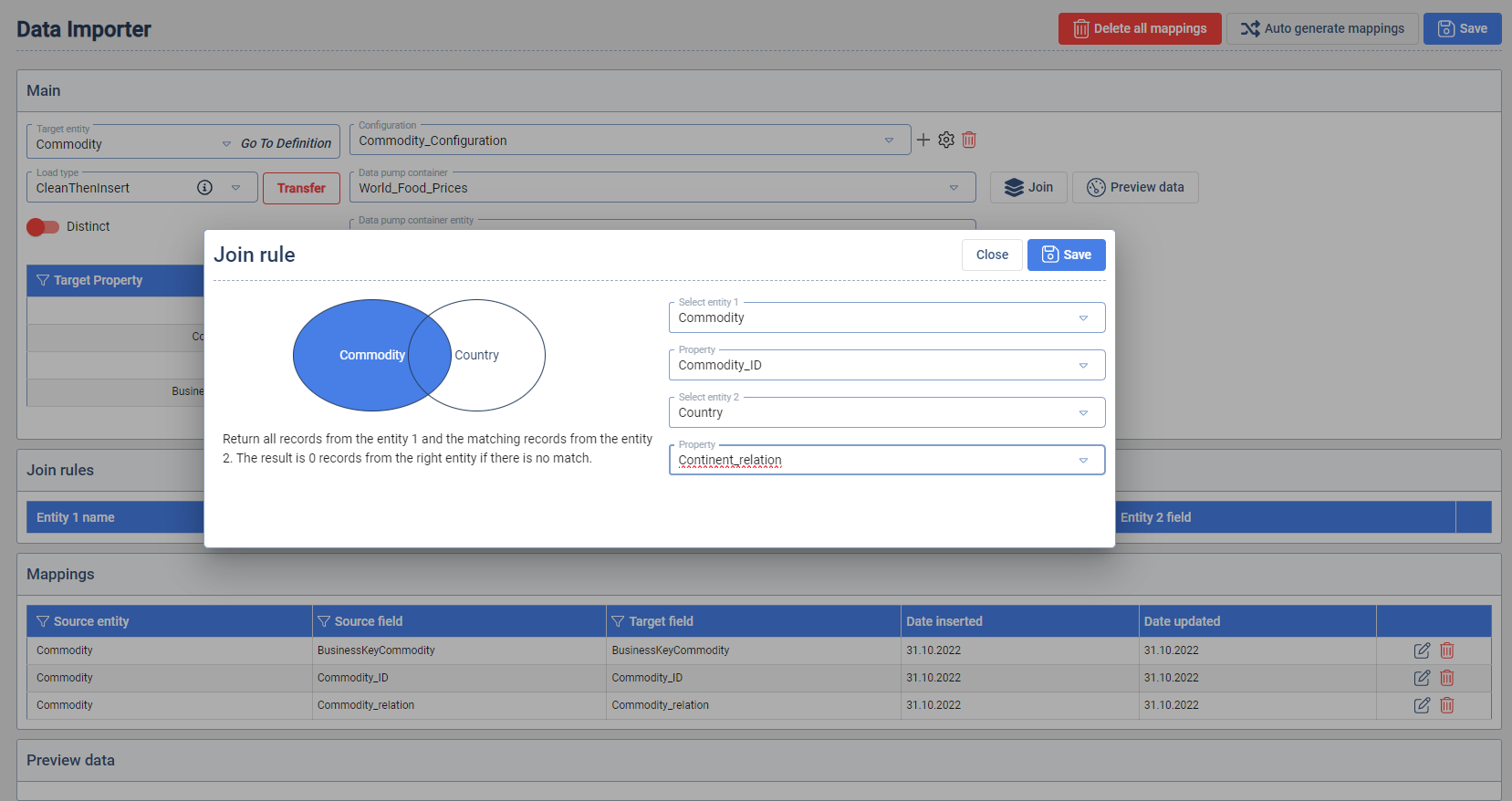
Joins
Joins enable integrate source entities which are provided from the selected Data Pump. This functionality enables that one Target Entity can receive data from multiple source entities. To create a Join between two entities, select the entities and their properties that connect them in the Join rule.
Configurations
Configurations enable Data Context Hub to load one Target Entity with data from multiple source entities which are provided from different Target Entities. One mapping configuration can have multiple sources. By default, when the user starts with defining a mapping, the system creates a default configuration. In case the data from other sources should be integrated the user needs to define more configurations and again create new mappings, since adding a new configuration will potentially add different source columns.
To add a new configuration you need to press the + icon. After that the configurations window opens. Fill in a title, description and select the container you want to connect with the configuration. Then press the Confirm button. After that you can select the desired source entity.
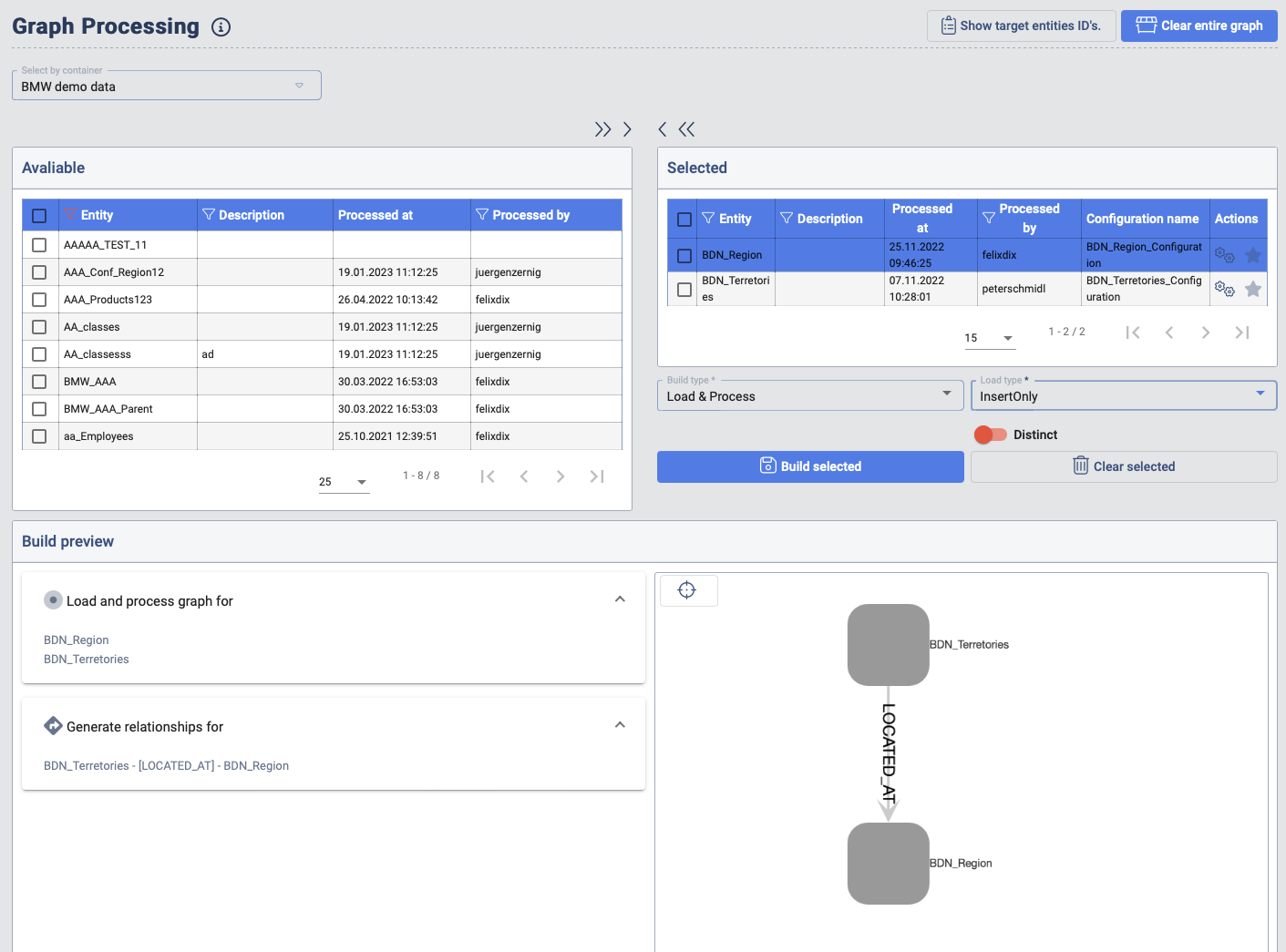
Graph Building - Graph Processing
To generate the nodes in the knowledge graph, the processing needs to be executed. The user has the ability to select the Target Entities which should be included in the processing steps.
In order to also generate the relationships, the related Target Entities also need to be included into the selection. The user has the option to hit the star icon in the Actions column which will also add all the related Target Entities to the selected Target Entity.
The graph processing supports multiple types of building the knowledge-graph:
- Load & Process: In this case the data will be loaded to the staging layer and processing will be executed. When this option is selected also the Load Type option is enabled. This option is the same as the one explained in chapter Data Importer.
- Process Only: In this case the data will not be loaded but only processing will be executed.
- Clear & Process: In this case all the nodes are deleted from the knowledge graph before the processing is executed.