2.2 Processing
As in chapter Data Engineering & Data Processing described the generation of the knowledge graph is called Processing. In this process, data is stored in the Data Context Hub Staging Layer and transformed into nodes and edges, then saved in the graph database Neo4j.
Generating the knowledge graph in the Data Context Hub can be based on different strategies:
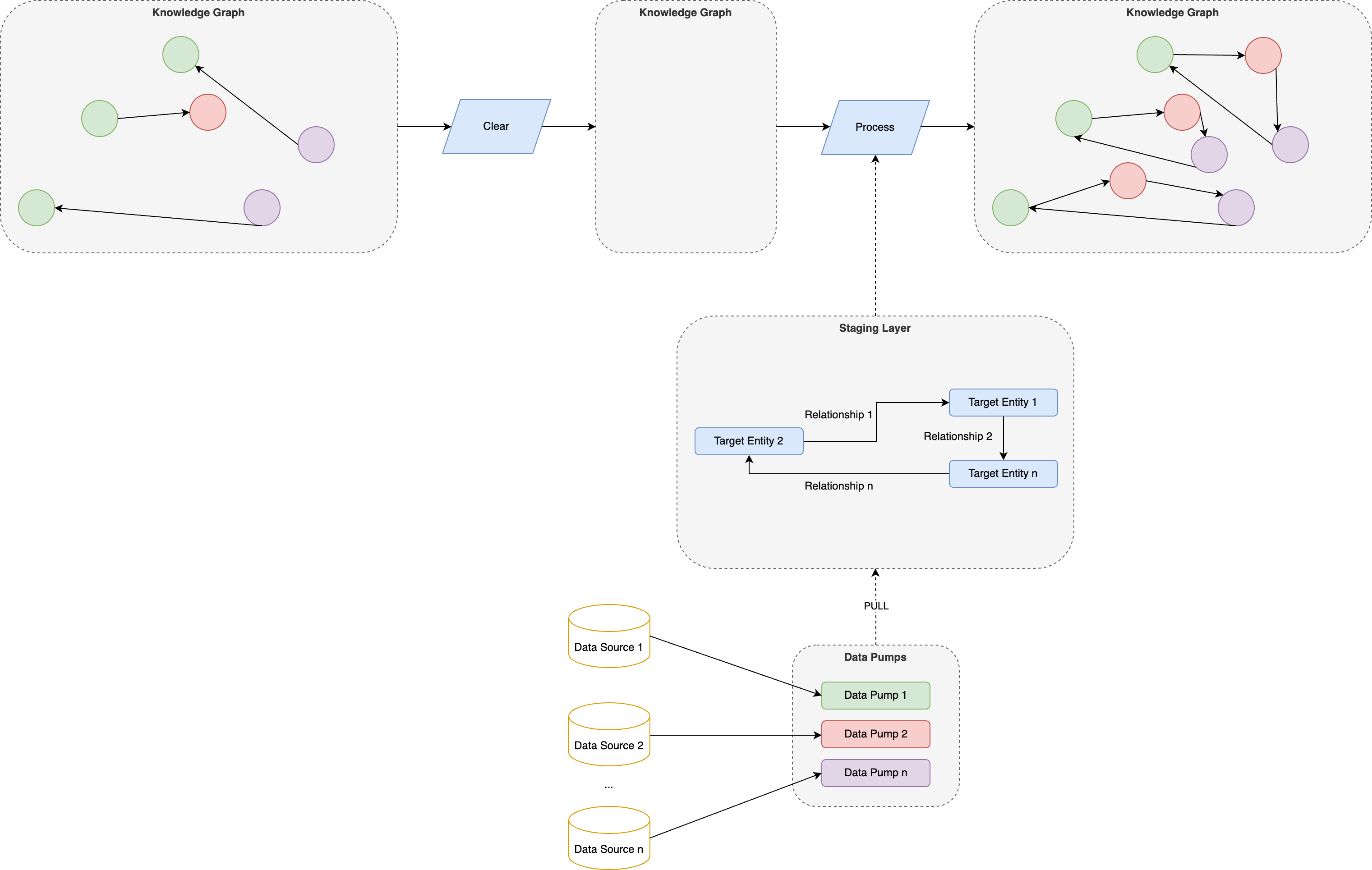
- Clear & Process: In this strategy, we clear the knowledge graph before processing. In this case, all the nodes and edges are removed, and new ones are generated. This strategy is appropriate in cases where the amount of data is not too big and the time to process is low.
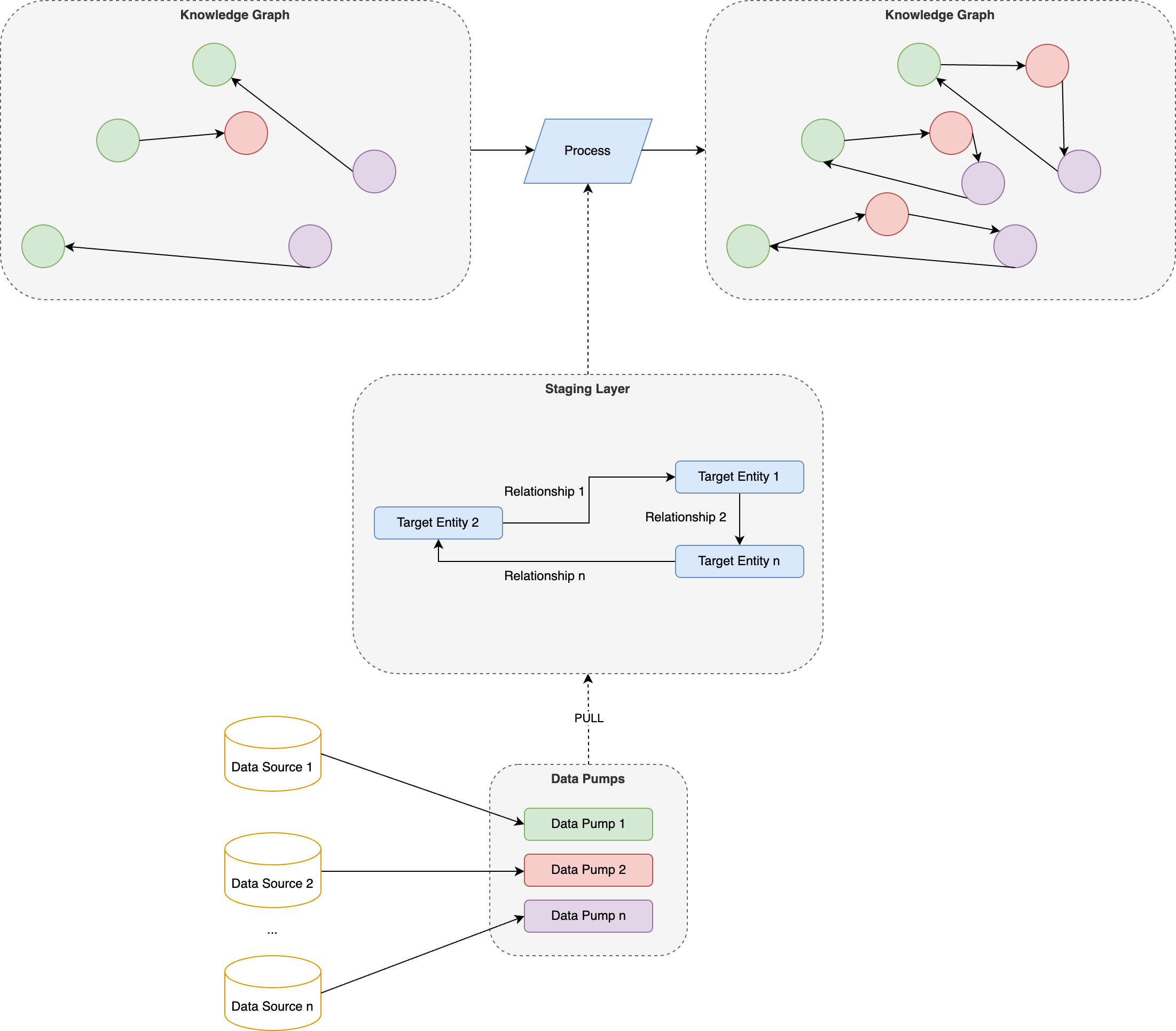
- Additive processing: In this strategy, the existing nodes are not cleared from the graph, but those nodes, that are already present in the graph are being updated. Those that are new in the staging layer but not in the graph will be created. Those nodes which are not present in the staging layer will be deleted from the graph. This strategy is applicable in cases where the knowledge graph is larger in size and regenerating from the staging layer would take too much time and system resources.
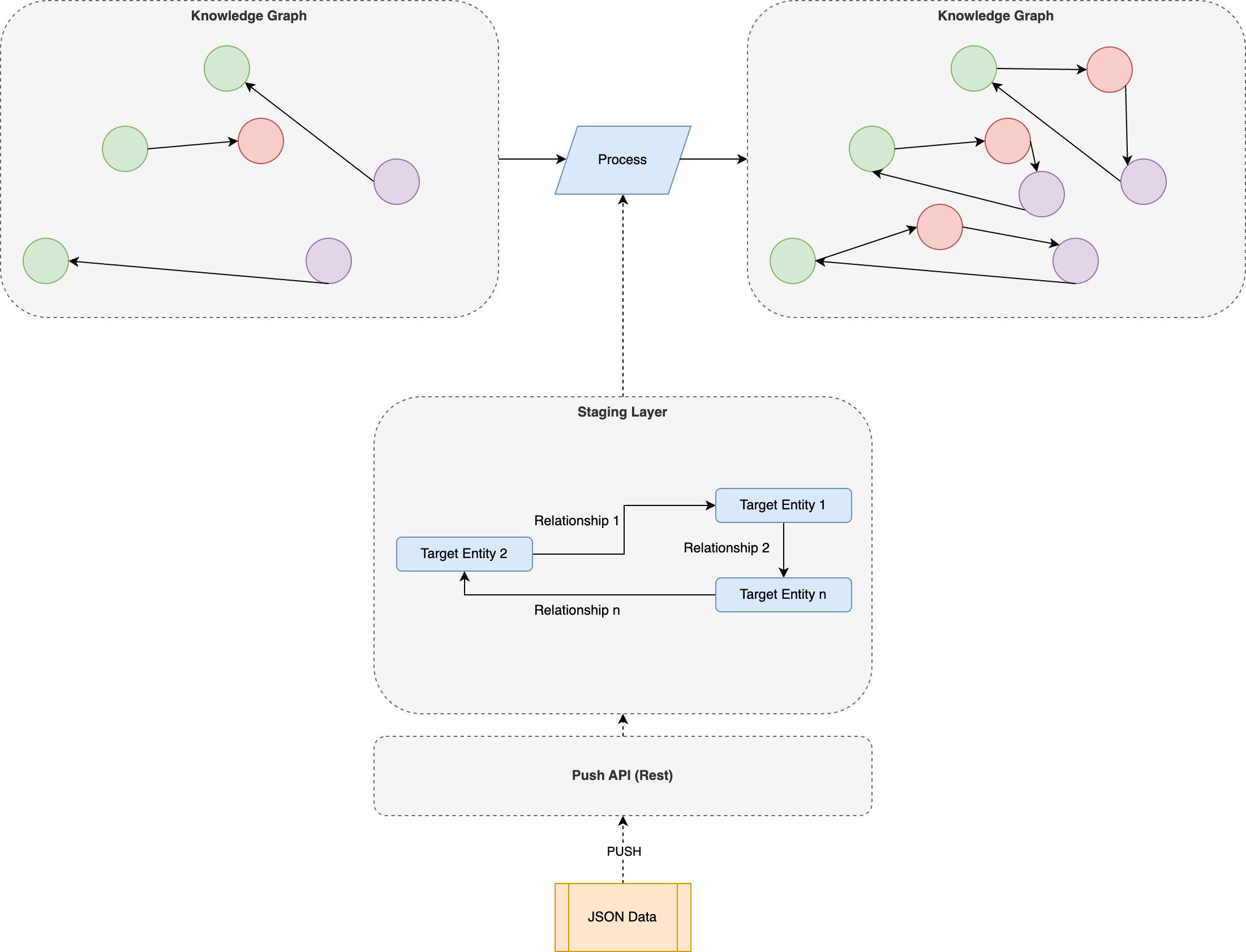
- Partial Processing: In contrast to other strategies partial processing is utilized when data is not pulled from an external source but pushed into the Data Context Hub via the Push API. When pushing data to the Data Context Hub the API allows for triggering the processing after the data arrives in the Target Entity. In this case, only the newly arrived records of that target entity will be processed into the knowledge graph. This strategy is applicable in cases when low latency is required between the time data is generated in the source or arrival in the Staging Layer and the time when the data is integrated into the knowledge graph.